

K2 Think breaks the scaling spell; Meta is paying $55 per hour for AI characters; Mistral emerges as the OpenAI of Europe; Ralph Lauren's AI era; CNBC goes behind the AI talent wars
Box CEO on AI's era of context; Vinod Khosla debates AI valuations; Microsoft AI CEO says machines are not conscious; Sal Khan on AI and education; MAGA populists call for war against AI and big tech

For the past three years, the conventional wisdom in AI was a kind of physics envy: if you want better foundation models, obey the scaling laws and feed ever more tokens into ever bigger networks.
We’re starting to see that conventional wisdom break, first with GPT-5 which was not a scaled model, despite what a clueless Gary Marcus claimed in his amateur hour op-ed for the New York Times.
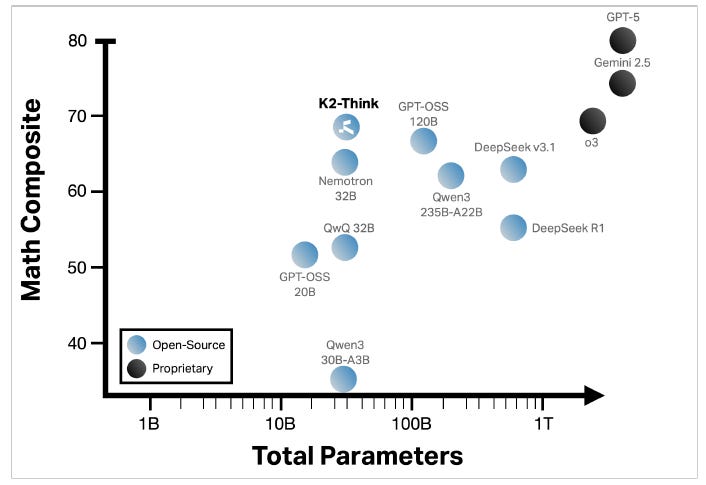
Then along came K2 Think, a 32 billion parameter model from MBZUAI and G42. Built on an open Qwen2.5-32B base and released with code and weights, K2 Think shows that careful post-training, smart test-time compute, and hardware-aware inference can get you remarkably close to today’s frontier on math and hold its own in code and science, without a trillion-parameter physique or a FAANG-sized budget.
K2 Think is a system based on a six-pillar recipe that was developed in three phases.
Phase one started with long chain-of-thought supervised fine-tuning (SFT) on curated traces (AM-Thinking-v1-Distilled). Early training moved the needle fast on competition math (AIME 2024 ~79.3% pass@1; AIME 2025 ~72.1%), then plateaud, which provided the team with a useful signal for where to lean next.
Phase two involved reinforcement learning with verifiable rewards (RLVR) across six verifiable domains via the Guru data set. This data set includes ~92k prompts spanning math, code, science, logic, simulation and tabular tasks, implemented with GRPO in the verl library. RL from a strong SFT checkpoint brought modest absolute gains; the same RL recipe from the base model grew much faster on AIME, hinting that heavy SFT can constrain exploration.
Phase three was about test-time improvements, focused on two specific aspects: first, a “Plan-Before-You-Think” approach where an external planning agent pulls out key concepts and drafts a high-level plan that’s appended to the prompt. Then, Best-of-N sampling which generates multiple answers and picks the best via pairwise LLM judging. After experimentation, N=3 provided the cost/benefit sweet spot. Alone, BoN delivers most of the lift; combined with planning, it adds 4–6 points across hard math benchmarks.
Additionally, the technical report describes how the team used speculative decoding and the Cerebras Wafer-Scale Engine (WSE is a massive wafer-scale integrated processor for AI training and inference) to achieve unprecedented inference speeds for K2 Think.
WSE delivers approximately 2,000 tokens per second per request, representing a 10x improvement compared to what Nvidia H-class GPUs can deliver. This dramatic speed-up fundamentally transforms the practical usability of long chain-of-thought reasoning, turning minute-long waits into seconds and making BoN + planning feel interactive, not academic.
Put differently: the team compressed model size and moved the “scale” to where it pays: the post-train recipe and the test-time budget.
Okay, but does it work? The math benchmarks say yes. On composite math (AIME 2024/2025, HMMT-25, Omni-MATH-HARD), K2 Think posts a 67.99 average, ranking it at the top among contenders in its open weights class and it even edges bigger open models like GPT-OSS 120B (67.20). The point isn’t that size never matters, it’s that careful post-training and test-time scaffolding can reclaim a lot of the curve.
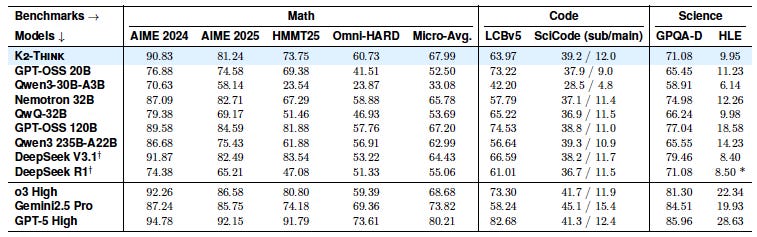
This isn’t a one-trick contest crammer: on LiveCodeBench, K2 Think hits 63.97; on SciCode, 39.2/12.0 (sub/main); on GPQA-Diamond, 71.08. That’s competitive or better within its class and in striking distance of much larger systems on science Q&As.
Two pragmatic results jumped out to me:
BoN vs. planning: BoN does the heavy lifting; planning adds a meaningful but smaller delta. The combination wins: e.g., AIME 2024 improves from 86.26 (SFT + RL) to 90.83 (Plan + Bo3); similar gains are achieved on AIME 2025, HMMT-25, Omni-HARD.
Planning trims verbosity: structured prompts led to shorter outputs (up to ~12% token reduction) and better answers. That’s rare: more thinking, fewer tokens.
There’s also a sobering takeaway: constraining max response length during RL hurt performance and didn’t recover with more training, evidence you can’t squeeze the chain-of-thought and expect the same reasoning paths to re-emerge later.
Until recently, the dominant mental model was “scale or stale.” K2 Think offers a different trade: a 32B open model that’s fast to iterate, accessible to research labs and startups around the world, and extensible with high-quality data and a few hundred GPUs rather than a sovereign compute budget. Because weights and code are out, anyone can extend the SFT/RLVR recipe, tweak the planning agent, change the verifier, or push N above 3 if their latency budget allows. The result is an R&D loop that is closer to software engineering than mega-pretraining: you can measure, ablate, and ship.
Hardware is part of the story. BoN and agentic orchestration are only fun if you’re not waiting around. The WSE’s on-chip weights and memory bandwidth make best-of-3 feel cheap; 32k-token chains go from “coffee break” on H100s to ~16 seconds. That unlocks interactive, human-in-the-loop reasoning workflows, exactly where open models can differentiate.
There are some caveats, of course. K2 Think’s “Safety-4” macro score sits at 0.75: strong on refusing harmful content (0.83) and conversational robustness (0.89), weaker on cybersecurity/data-protection (0.56) and jailbreak resistance (0.72). Translation: solid baseline, but indirect/jailbreaky attacks remain a to-do, as we saw a few hours after release.
Secondly, RL from a strong SFT checkpoint gained only ~5% on AIME 2024 versus ~40% when starting RL from the base model, evidence that heavy SFT can “lock in” habits and limit exploration.
Finally, the paper’s method is admirably explicit (16× pass@1, shared decoding hyperparams), but test-time scaffolds like BoN and LLM-as-judge have operational costs and failure modes. The good news is that K2 Think’s open release lets the community reproduce (or break) these claims.
K2 Think won’t dethrone the very largest proprietary models across every domain, but it doesn’t have to. It demonstrates that parameter-efficient reasoning is real, that test-time compute is a first-class lever, and that hardware choices can flip the UX from batch to interactive.
In practical terms, it lowers the barrier to entry: small labs or startups can start from 32B, adopt the six-pillar recipe, and specialize (math today, code or science tomorrow) without rebuilding a pretraining pipeline from scratch. That unlocks a more competitive, more pluralistic supply chain for reasoning models.
And now, here are the week’s news:
❤️Computer loves
Our top news picks for the week - your essential reading from the world of AI
WSJ: AI Startup Founders Tout a Winning Formula—No Booze, No Sleep, No Fun
TechCrunch: Box CEO Aaron Levie on AI’s ‘era of context’
The Verge: Sierra CEO Bret Taylor on why the AI bubble feels like the dotcom boom
The Information: Are AI Valuations Bonkers?
Wired: Microsoft’s AI Chief Says Machine Consciousness Is an 'Illusion'
Business Insider: Meta is paying contractors up to $55 an hour to build AI chatbot characters
The New York Times: United Arab Emirates Joins U.S. and China in Giving Away A.I. Technology
Bloomberg: Mistral Emerges as Last, Best Hope for European AI Contender
The Verge: Sal Khan is hopeful that AI won’t destroy education
CNBC: Behind the AI talent war: Why tech giants are paying millions to top hires
The Verge: MAGA populists call for holy war against Big Tech
